编译原理概述
在编译性语言中,当使用类似 build 指令进行编译时,在其内部会严格进行下面机制的转换,从编码层转变为机器语言层或是汇编语言,从而运行代码赋予的操作在此机器上。但是这一过程对于我们使用者来说是便捷的,不用过多的考虑构建的过程,只需要注重其结果。
在编译型语言中,常见编译过程包括:
- 词法分析:源码转换为 Token
- 语法分析:将 Token 转换为 AST
- 语义分析:分析校验 AST 的合法性
- 代码生成:AST 到 SSA 的转换
在上述流程中,其主要是将源码一步步的抽象化,这种也像在设计一种编程语言时,通过将理念抽象,获得更直观的理解,也是方便编码从业者的使用。从这一方面可以看出,对于编译也是如此。从可读语言进行抽象化,其目的旨在后续分析做铺垫。
所以说编译器主要实现的步骤则是从字符序列转换为 SSA,而这一过程,在 Golang 中可通过命令进行显式输出为 HTML。
SSA 生成
例如最为常见的一个 Go 代码(下文所有分析依据于此片段):
1 | package main |
这段无疑是最为熟悉,但从保存文件到运行,中间做了什么操作,对我们来说属于黑盒,得到的只有结果,而中间的过程是不可见的。所以作为有追求有梦想的开发者,必然是会将盒子打开来一探究竟,它是如何在盒子中运作的?
在使用 Go自带的 run 命令后,程序从编译态(Go 为静态语言)到运行态的过程,首先经过编译器,而其主要负责以下操作:
- 通过 Token 构建 AST,构建抽象语法树。当前阶段主要负责分析、检查和代码生成
- 加载 Runtime 运行,在 main 函数之前加载代码,比如 GC、Schedule 等
Terminal 中执行命令:GOSSAFUNC=main go build main.go, 即可在编译过程中将转换为 SSA 的流程暴露出来。命令执行后,会在当前目录下生成文件 ssa.html。SSA(Static Single Assignment)是指静态单赋值,也是编译器优化和转换源代码的中间表示形式(这是编译的最后阶段,暂时不做解读)。
命令执行输出结果如下图所示
将ssa.html文件打开,在浏览器中显示如下图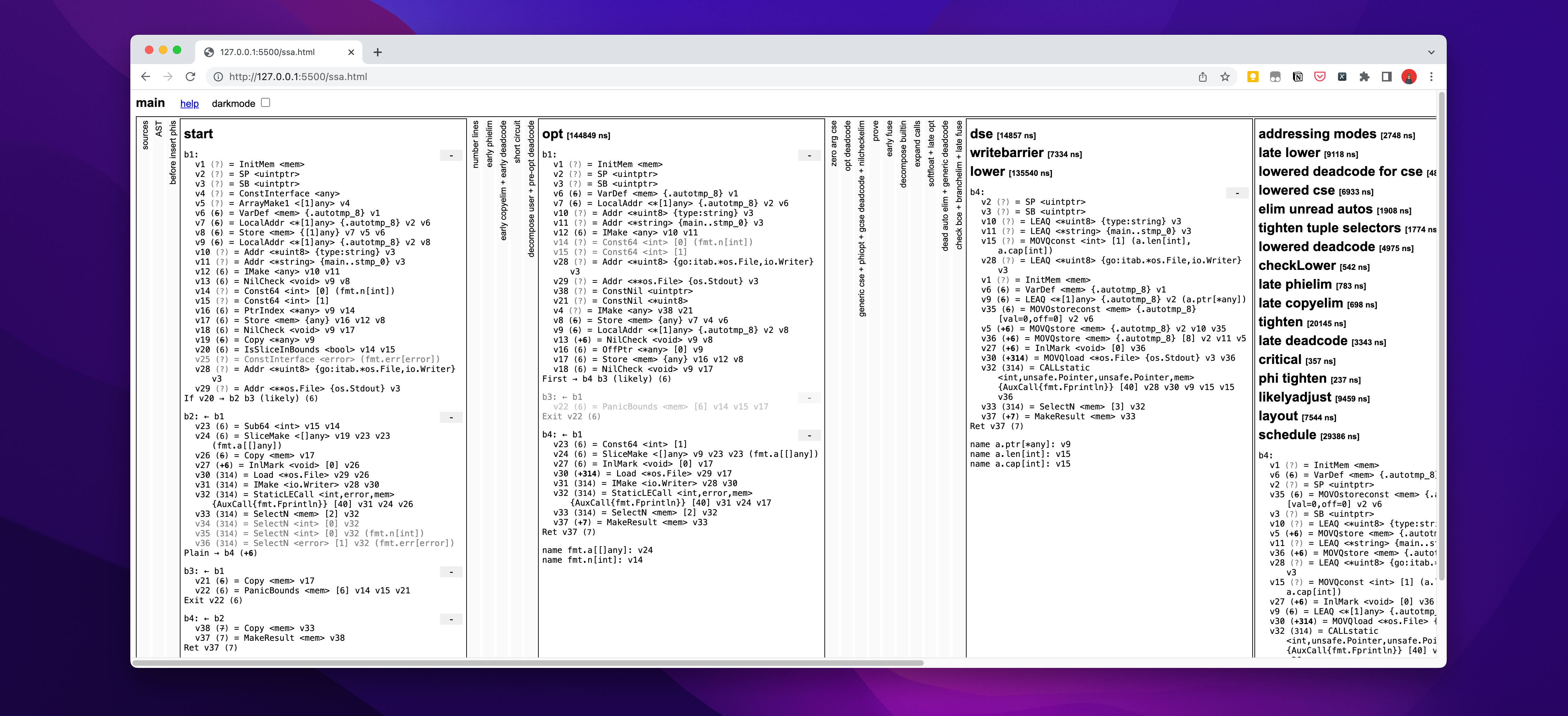
可以大致浏览下页面,从 Source Code 到 SSA 的转换,这就是在编译过程中,将我们可读的字符序列,转换或是说抽象为特定结构。
词法分析
词法分析(Lexical analysis) 是将字符序列(String)转换为记号(Token)的过程。进行词法分析的程序或函数称为词法分析器(Lexer),也叫做扫描器(Scanner)。
引用来源:
- Token定义:
./src/cmd/compile/internal/syntax/tokens.go - Scanner实现:
./src/cmd/compile/internal/syntax/scanner.go - Wiki: https://en.wikipedia.org/wiki/Lexical_analysis
扫描器
扫描器即 Scanner,是此词法分析的第一阶段,通常基于有限状态自动机。扫描器通过读取源码的字符序列,并根据事先定义的词法规则,识别和生成不同类型的记号。每个记号代表源码中的一个语法单元,比如说语言关键词,标志符等,而代码中的注释、空格、换行和制表符等在此步骤被忽略。记号是代码的最小语法单元,为后续编译使用。
记号生成器
引用在Wiki中的释义
记号化(tokenization)即将输入字符串分割为记号、进而将记号进行分类的过程。生成的记号随后便被用来进行语法分析。
举个例子说,有一句话为 The harder you do, the more free you are.,对于我们来说,很容易明白其意思,但却对计算机而言,是无法理解的,所以还是按照前文所说,将句子抽象/结构化来表示。
字符序列转换为JSON格式,下面便是一种计算机能理解的数据结构,
1 | { |
代码实现
在词法分析阶段,Go 源代码会被分解成一系列的词法单元,也就是 Token。这些 Token 是代码的最小语法单元,包括关键字、标识符、操作符、常量等。词法分析器会按照一定的规则扫描源代码,并将其转换成一系列的 Token 序列。
在 Go 标准库中也实现了 Token 的生成函数,源码位置已在文章开头标记出。下述代码是在标准库中拷贝(其中稍有更改 src 内容,统一解析代码)。
1 | package main |
代码运行输出结果如下,其主要目的是将可读的代码转换为特定语法。
1 | go run main.go |
执行后的输出如下:
- 第一列:
2:2,通过查看源码可以看到,第一个2表示的Line,第二个则是Column,代表当前输出代码的位置。 - 第二列:是在Token中定义的类型(
token.Token),实际类型为int - 第三列:对应的是源码中被翻译的字符序列
结语
在编译过程中,词法分析不只是为编译器,也是构建解释器的重要步骤之一,通过将字符串转换为记号,为后续的语法分析和转换过程提供基础,下一步则是进行语法分析,将词法分析的记号转换为抽象语法树。
本文只是个人对编译原理部分的拙见,如有错误,还望大佬们指教一二。